This week we discussed Association Rule Mining, which is initially used for Market Basket Analysis. Market basked Analysis is used to find out how items that customers buy are related to each other, and how frequently they are bought together. All data using the Association Rule Mining are categorized, and it is a poor option for numeric data.
Association Rule has multiple types:
Actionable Rules
Trivial Rules
Inexplicable Rules
We also learned key concepts such as support and confidence.
Support is the rate of frequently bought items or the combination of items bought frequently.
Confidence is the conditional probability of occurrence of a consequent, then providing the occurrence of an antecedent.
The Apriori Algorithm has a two-step approach:
Frequent Itemset Generation
Rule Generation
The Steps are:
Set minimum support and confidence and calculate the frequency table for the itemset
Generate K-itemset from the previous itemset and count each itemset support
Topic: Clustering K-Means, Learning from Observation
This week we reviewed about supervised, unsupervised and reinforcement learning. After the short review, we got into a part of the main material which is clustering techniques. We learned that clustering techniques is a part of unsupervised learning, and attempts to group and classify data into different segments. It can be applied to almost every known field, some examples include:
Marketing
Biology
Libraries
City Planning
etc.
We also learned several distance measurement methods, including the Euclidean distance and the Manhattan Distance. We also learned the two types of clustering techniques, which are Partitional and Hierarchical. Lastly, we learned another one of the main topics which is the K-Means Algorithm, and afterwards did a few exercise questions.
This session we discussed supervised vs unsupervised learning, and the parameters they require. We also learned the different types of formal languages such as fuzzy logic, propositional logic, etc. We also learned how to represent probability based on the case of events happening. Other key concepts we learned also includes:
Conditional Probability
Bayes Rule
Naive Bayes
We then did an exercise using Naive Bayes to figure out the probability of an event happening based on the conditions given in the question.
This session we discussed the concept of adversarial search, which is an algorithm which puts opponents into consideration when deciding the best possible move for a game. We went in more depth about the minimax principle, which talks about maximizing our chances on winning based on what the opponent decides to do.
We also discussed alpha and beta pruning, which is the elimination of certain branches based on the information we currently already have from the other branch. It is implemented using Depth First Search (DFS) and tries as to find the best path towards the solution.
The algorithm is applicable for both deterministic and non-deterministic games. We were tested with exercises in implementing these algorithms graphically.
This week we discussed about informed search, which includes algorithms like the A* algorithm and the Greedy Best First Search. We learned how to assign heuristic values, what they mean and how the algorithms we have learned today use them to function.
Another topic that was brought up was the local search, which includes Hill Climbing, Simulated Annealing and the Genetic Algorithm. For this session, the Genetic Algorithm was the one being mainly focused on. From what I noticed, most of the algorithms introduced from local search put in randomness in them for optimization purposes. The Hill Climbing uses randomness by exploring random neighboring nodes to get the optimum result. While the Genetic Algorithm uses mutation in the bit string to get different results.
This week we discussed multiple uninformed search algorithms, which are also known as blind algorithms. There are 5 algorithms we learned, which consists of BFS, DFS, UCS, DLS and IDS. The algorithms that we focused on in particular was the BFS and the DFS. Since we had already learned these two algorithms in the previous semester, the lecture was easier to digest.
Aside from the algorithms, we also learned the theory behind uninformed search strategies and knowledge agents need to formulate the decision behind their actions.
The first topic of the semester was that about the introduction to the course, final project requirements and basic concepts about AI and machine learning. Despite only hearing about AI and machine learning only in the recent years, I had only just learned that it was already being discussed from the 1950s. The class continued with the majority of information being covered relating to intelligent agents. Its definitions, the different types and the key concepts and ideas it follows. We also discussed AI of the present days and their capabilities, its history and applications in the field. Overall, I feel like this is going to be a fun course with a lot to learn and challenges ahead.
In order for a company to function it must have a system to organize its own resources. One resource that is crucial yet sometimes overlooked is human resources. A company must at all times have access to all the required data related to an employee. The required data includes but not limited their wages, leave allowances, work ratings, contract type, etc. in today’s era HR becomes a given when talking about any workplace.
In the interview we conducted we have surmised that a significant number of HR managers still have all their data in excel. This has its own share of problems such as field organization, scalability, and data integrity. We asked a number of questions such as “what do you use to store data?” and “What do you think can be improved?”. The answers we obtained as well as research results led to our conclusion that database might be a better means of data storage for this matter. Hence we have come up with the following problem statement:
How can the usage of databases improve the efficiency of an HR department in a company?
The above is the end goal of the project where everything is based on. Deliberations towards UI design, transaction requirements all have the above basis for the overall design of it.
Team members and Roles:
Rio Adi Nugraha: Database Designer, Database implementation, Interviewer
My job is to interview the target audience and then design the database to suit the needs of the company. I was given the excel spreadsheet with limited data. My job is to convert this excel spreadsheet into a cohesive relational database. I contribute with implementing the database into a server. Creating the table and connecting the foreign key is also part of my responsibility. After the product is complete and in between it is also my responsibility to communicate with the client to see if the product suits their preferences.
Hengky Sanjaya: Database Designer, Programmer
I am responsible to design the outline of database tables with team. Analyze the data from the company given in excel format and translate into the relational tables. Create and build the application in desktop platform with technologies of C# as main programming language and MySQL as database storage. Responsible to build features of application such as login, register employees, entry employee data, report, import data, etc.
Ryan Rusli: Database Designer, Programmer
I am responsible for designing a majority of the class models of the program and for most of the data management interface. I also contributed in the design of the database table with the other group members. I also handled most of the data insertion, retrieval, update and deletion functions and interactions with the database. I also created the employee management page which manages email, phone, address and job history.
Naufal F. Basyah: Report Check and Miscellaneous
I am mostly responsible for the report checks and details that need to be made i.e. ERD and relation description. I also contribute in a smaller scale in miscellaneous task as an extra pair of hands.
The first normal form dictates all the attribute within a relation needs to be single valued. This means that multiple valued attributes such as if a person has 2 jobs is converted into values within different rows. It is difficult to show that within the above diagram. There are examples showing this possibility was closed with our design. For example if an employee has multiple phone numbers. These phone numbers will have unique phone ID generated hence does not depend on the person rather it depends on the ID. There are some attributes we assume will be singular such as gender,KTP,and Nickname. With the condition set that these values are singular then all attributes should be singular in nature therefore adhering to the first Normal Form.
The second normal form dictates that there exists no partial dependency no non-prime attribute is dependent on any other subset of the primary key. Because we designed it in a way that all the tables have a unique primary key every attribute is determined by their respective primary key. The lack of composite keys means that no partial dependency is present within the database. Some of the tables might seem necessary however we designed it so it would be customizable if required later on.
The third normal form dictates there exists no transitive dependency between the columns. As shown previously all the attributes within a relation are dependent on their respective primary key and by extension and definition this allows the database to be in third normal form.
Sample queries
provide some samples queries (at least 5) to generate reports
Sample 1:
Query to generate the number of employees from both genders.
“SELECT Gender, count(*) ‘total’ FROM Employee GROUP BY Gender”
Sample 2:
Query to generate the number of employees for each marital status (single, married, divorced).
“SELECT MaritalStatus, count(*) ‘total’ FROM Employee group by MaritalStatus”
“SELECT * FROM employee e JOIN employeefamily ef ON ef.nik = e.nik join employeeaddress ea ON ea.employeenik = e.nik JOIN employee_phones ep ON ep.nik = e.nik where e.nik IN (SELECT nik FROM transaction WHERE enddate < now());”
Sample 5:
Query to generate a report that provides information on the amount of employees in the age groups of under 20 years old, between 20 and 30 and between 31 and 40.
WHERE enddate < now() AND (tr.positionid = 1 or tr.departmentid = 1)
) AS t
ON e.nik = t.nik;
User Interface
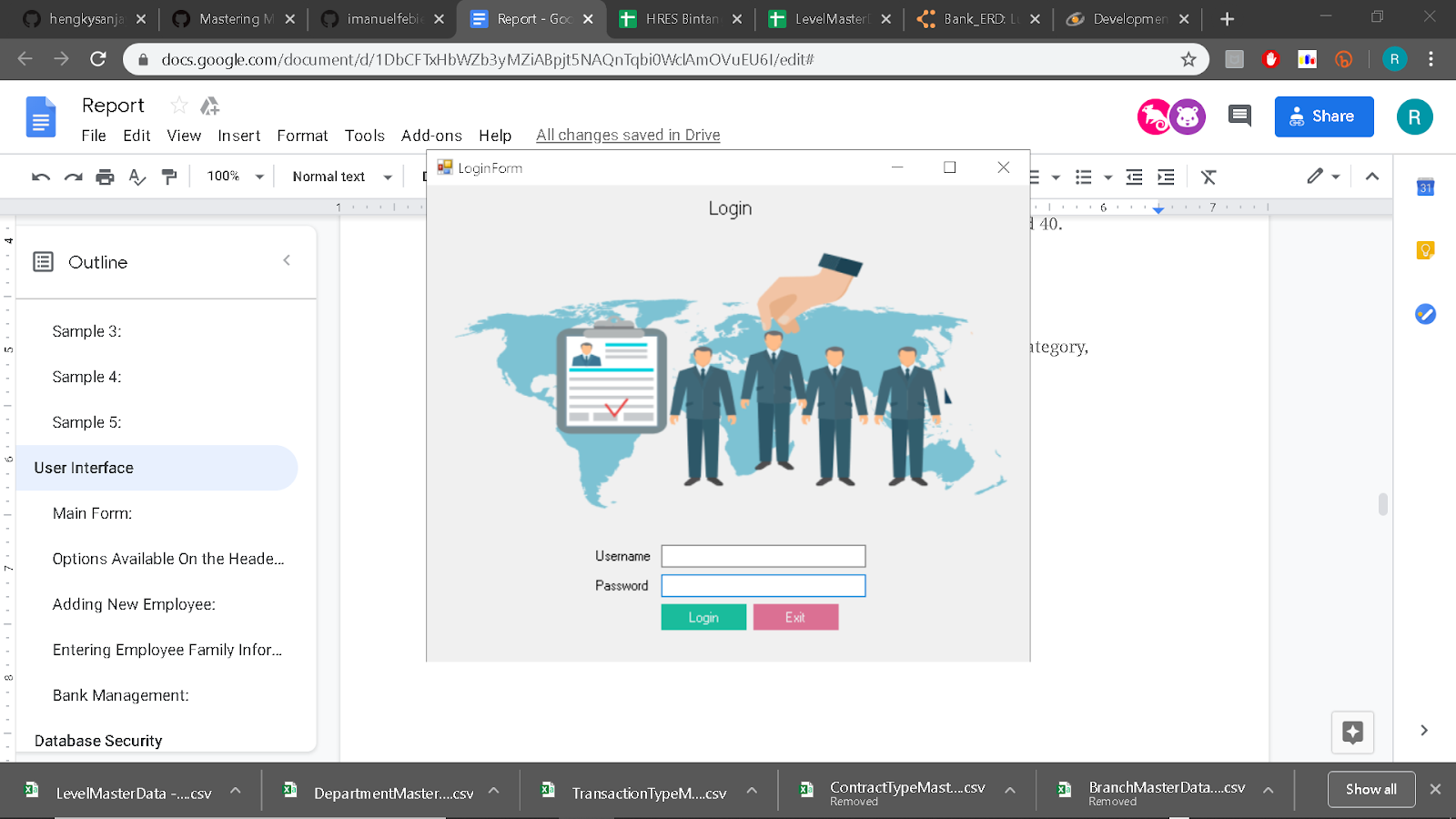
Login Screen:
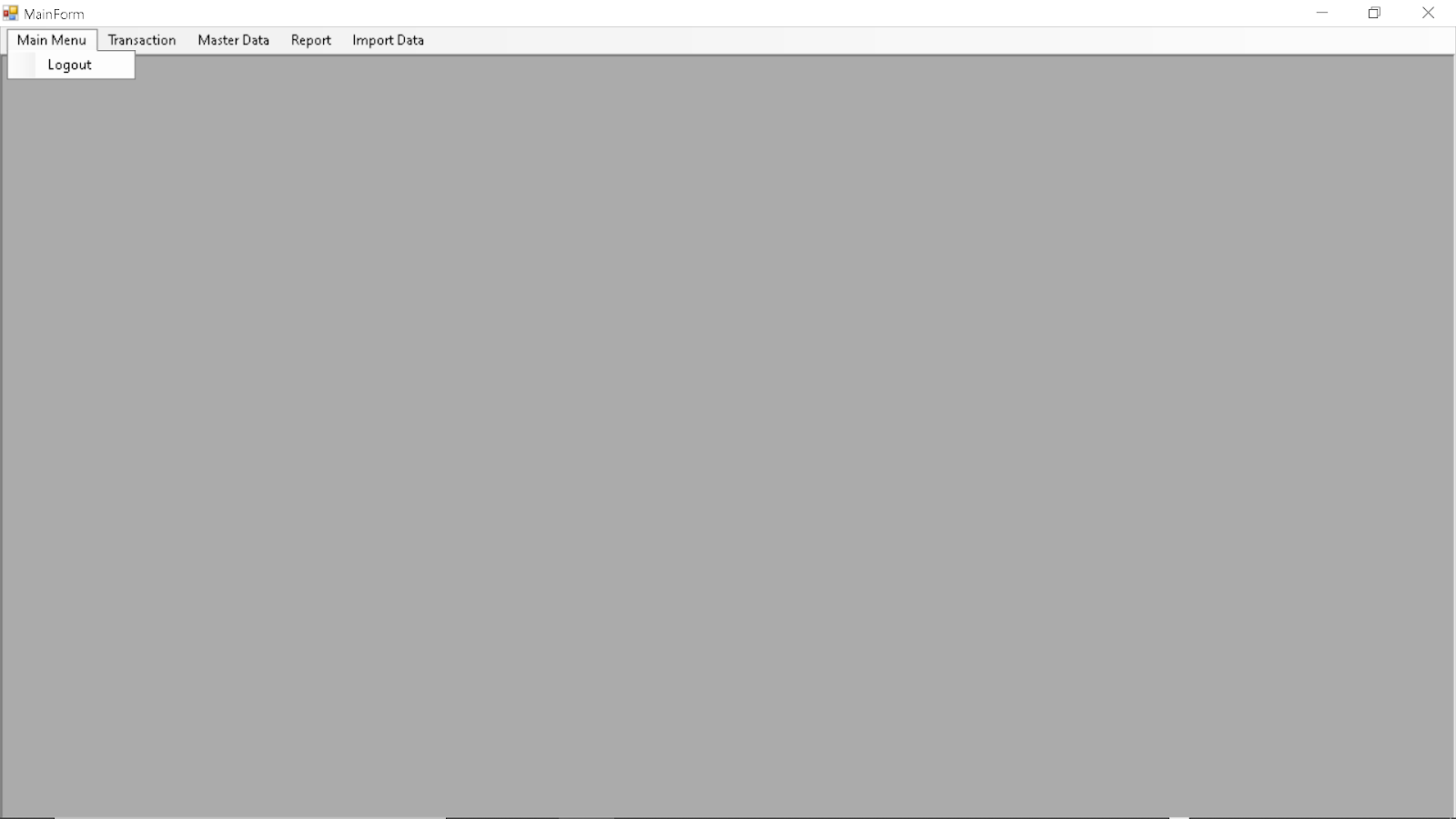
Main Form:
Options Available On the Headers:
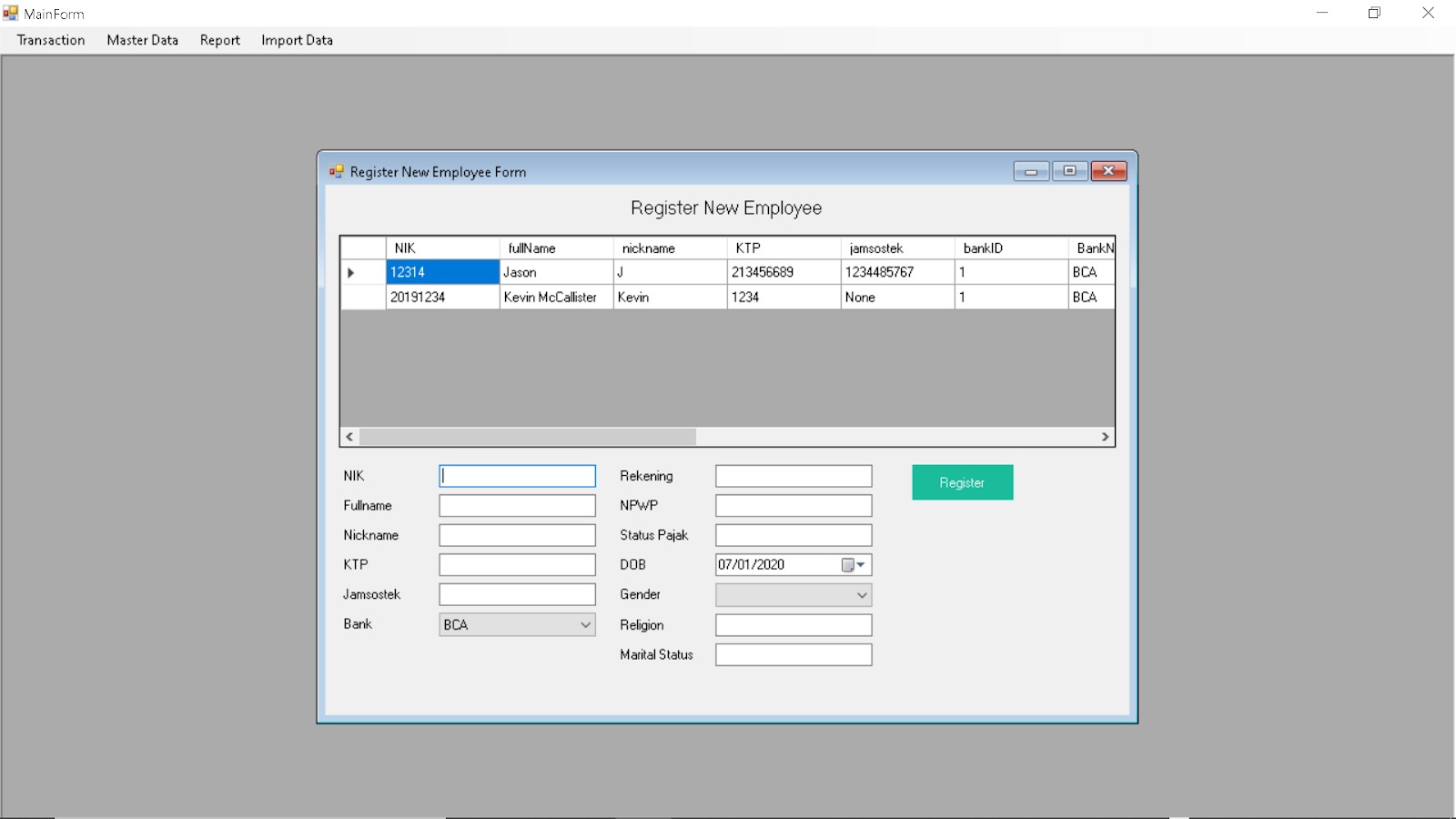
Adding New Employee:
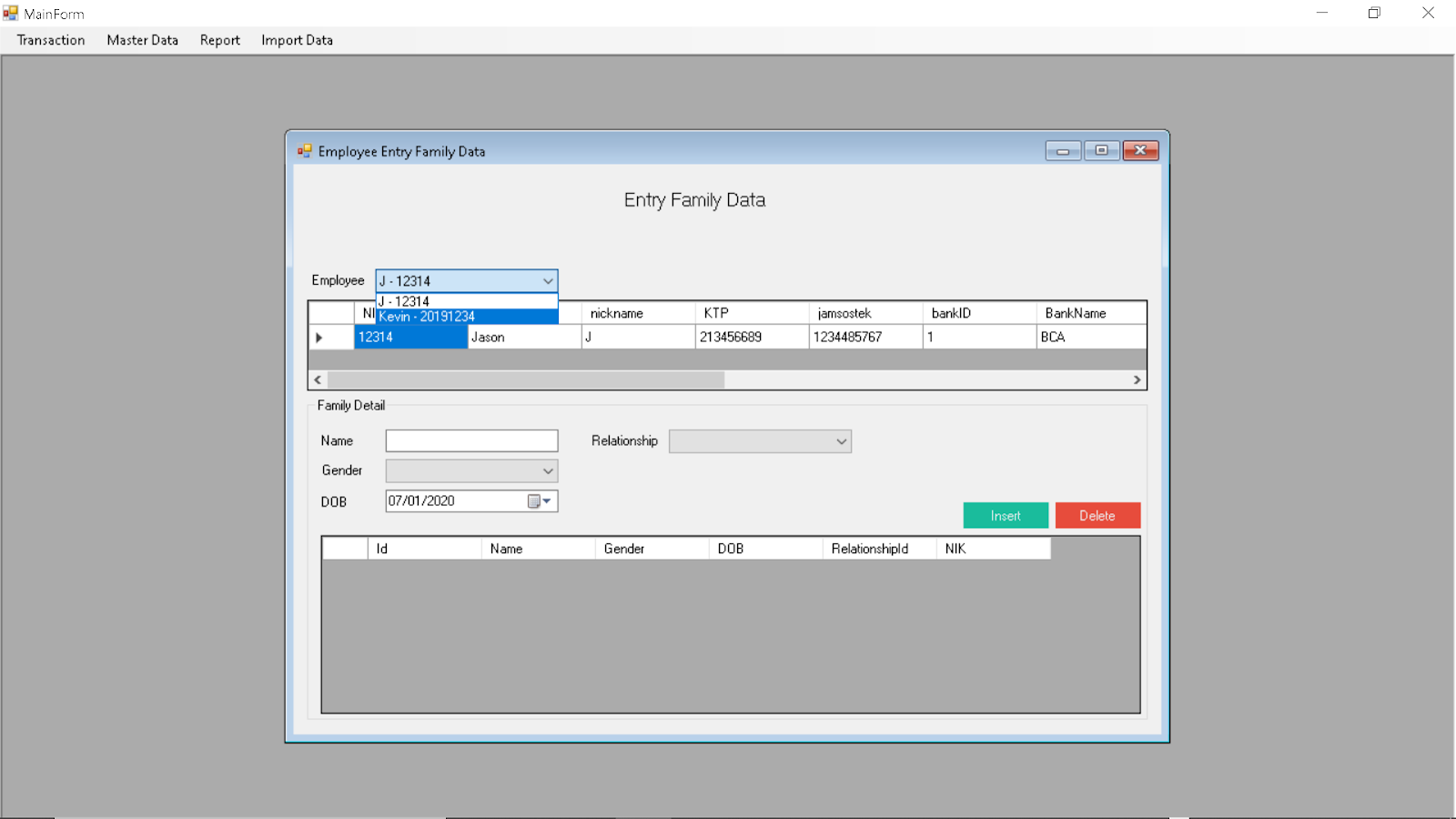
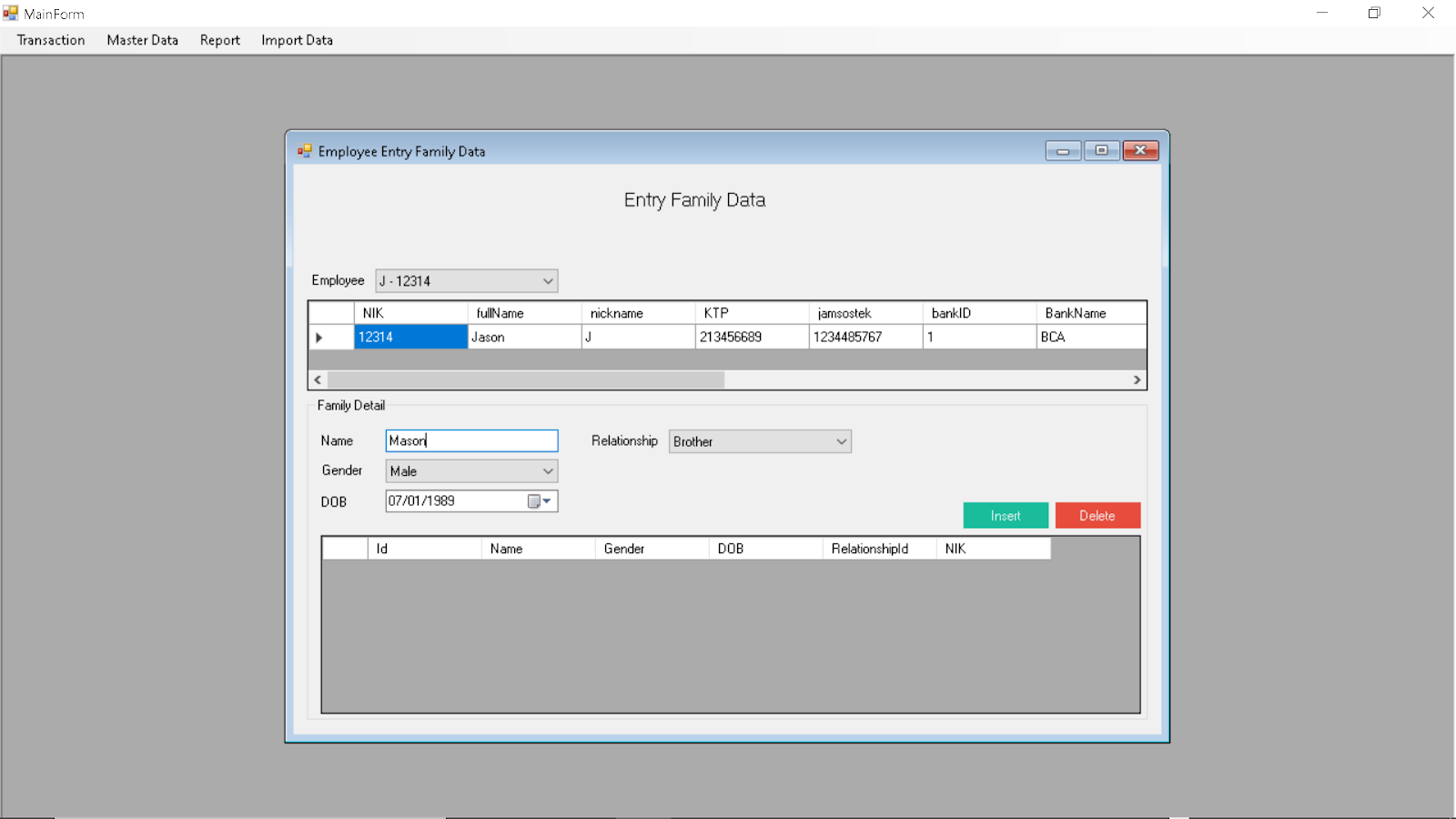
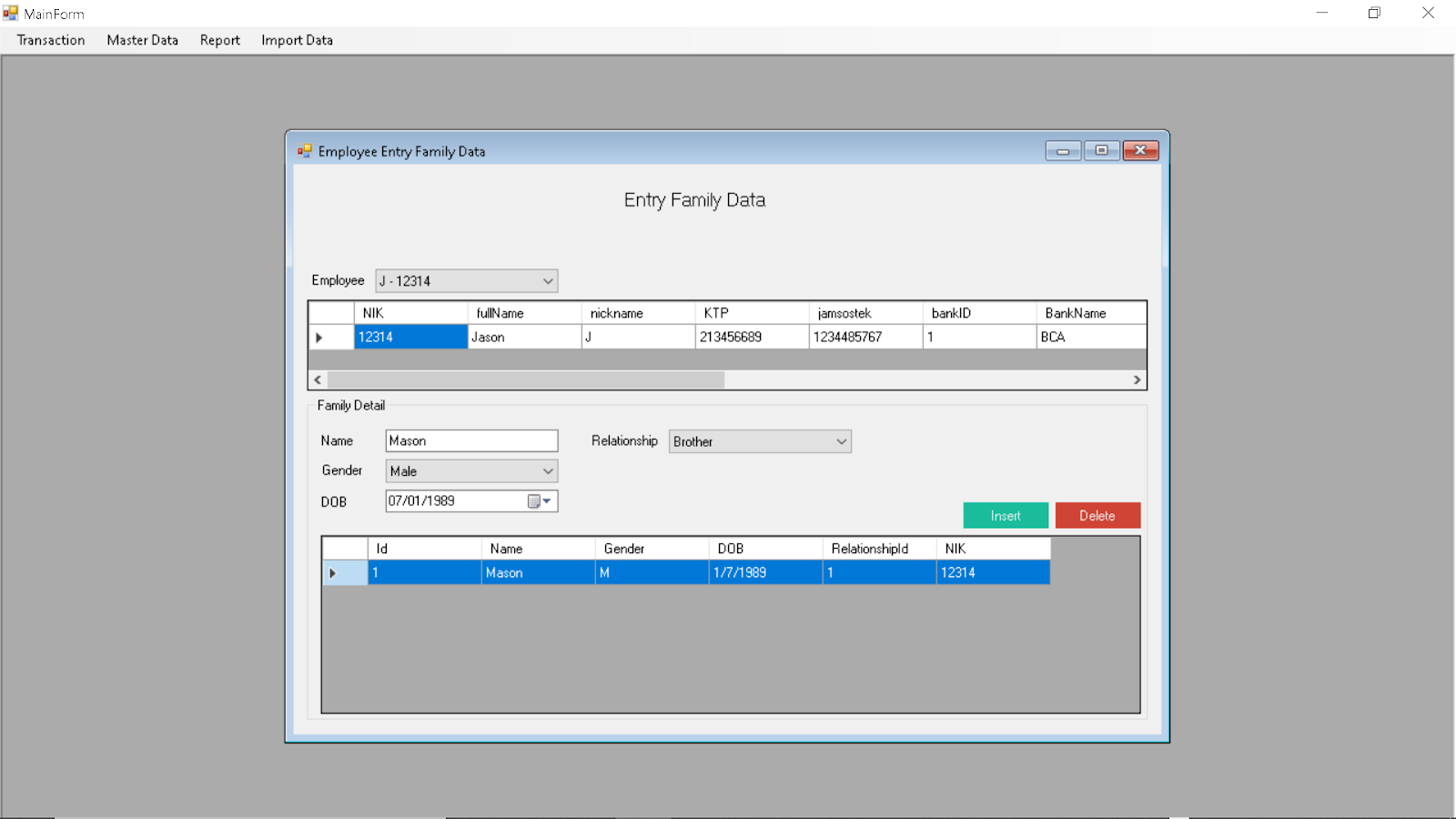
Entering Employee Family Information:
Selecting Employee
Adding Employee Family Relationship
Deleting Relationship
Entry Phone Data
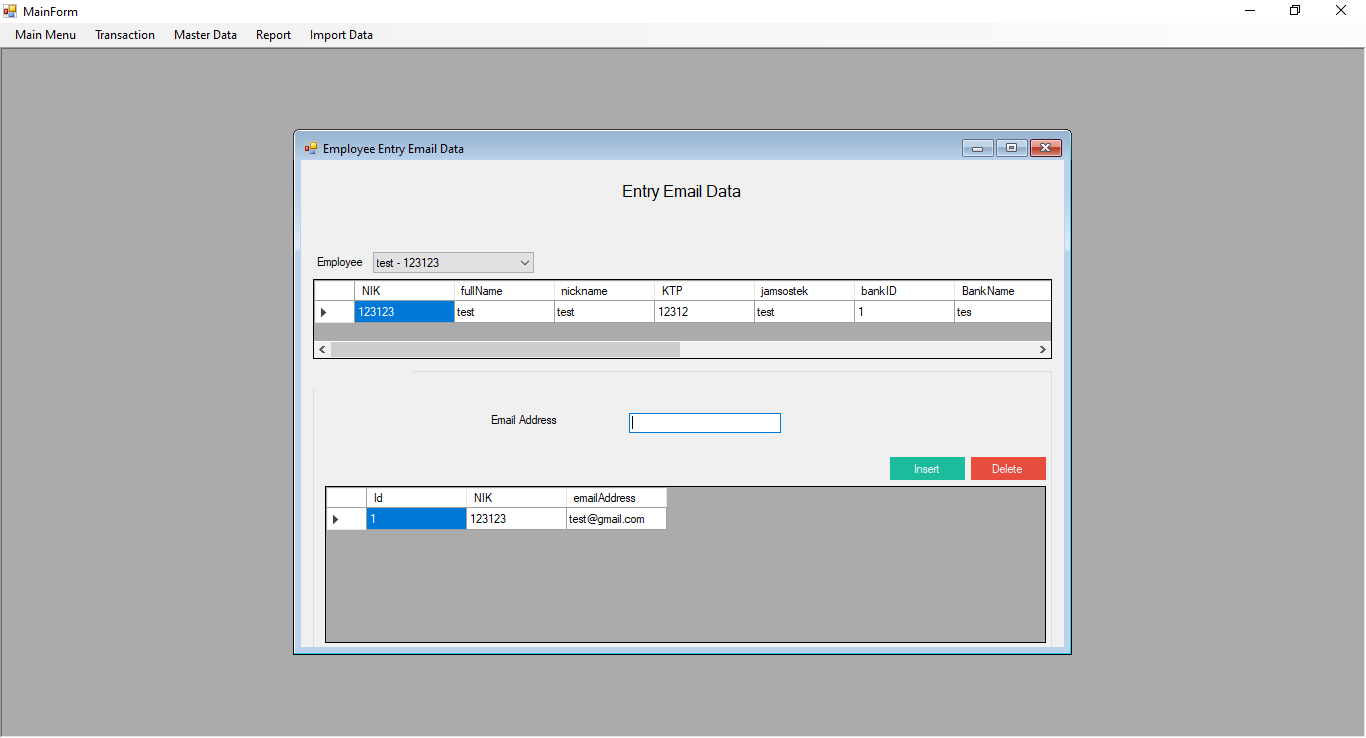
Entry Email Data
Entry Address Data
Entry Education Data
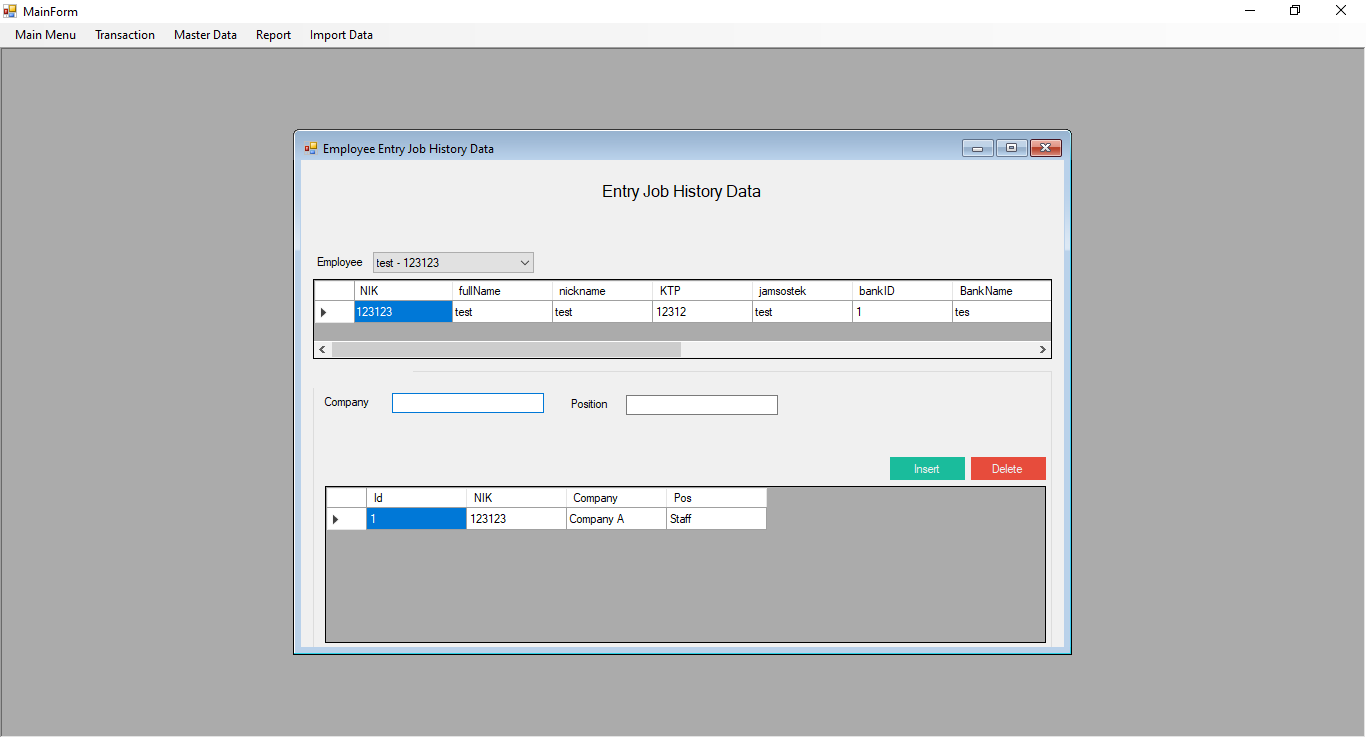
Entry Job History Data
Register New Employee
Edit Transaction
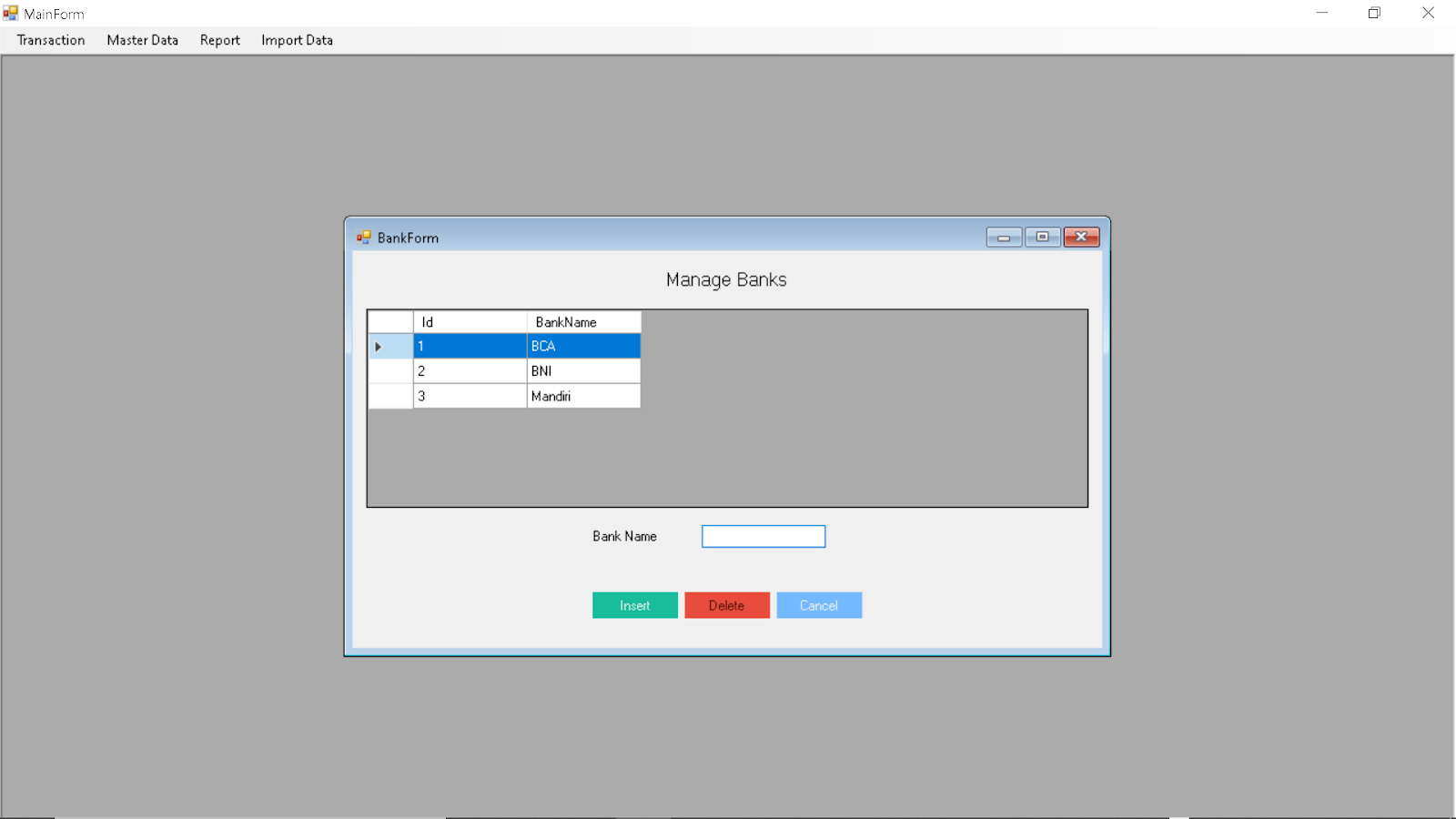
Bank Management:
Branch Management:
Contract Management:
Department Management:
Level Management:
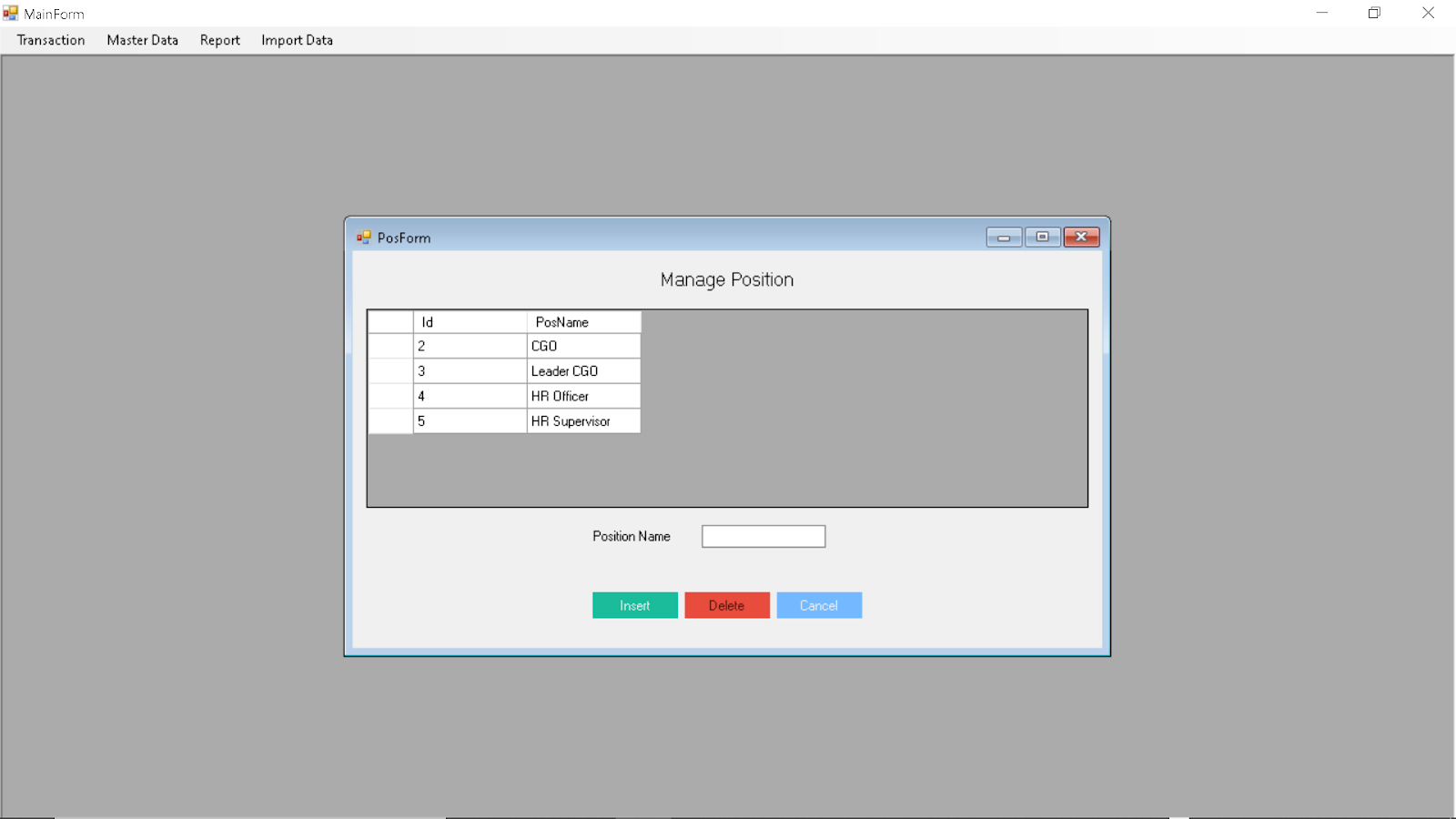
Position Management:
Transaction Type Management:
Employee Report:
Transaction Report:
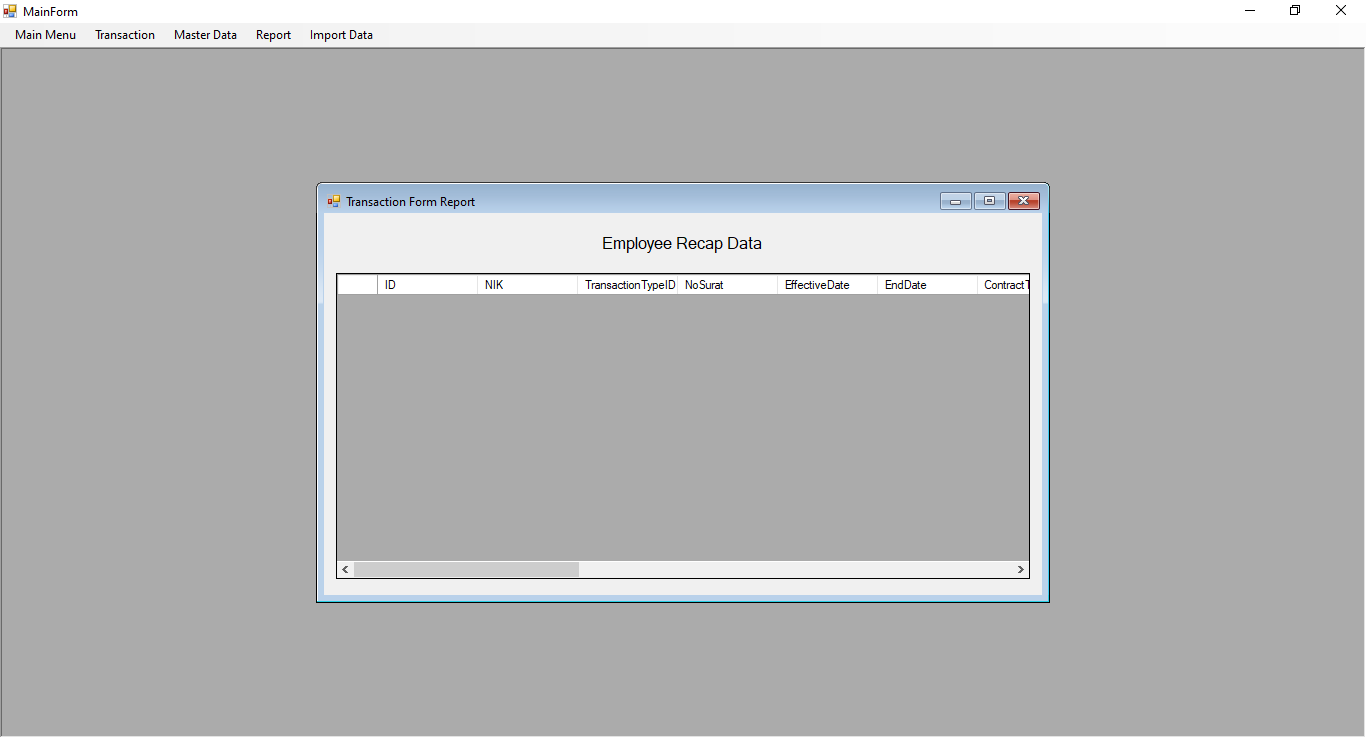
Employee Recap Data
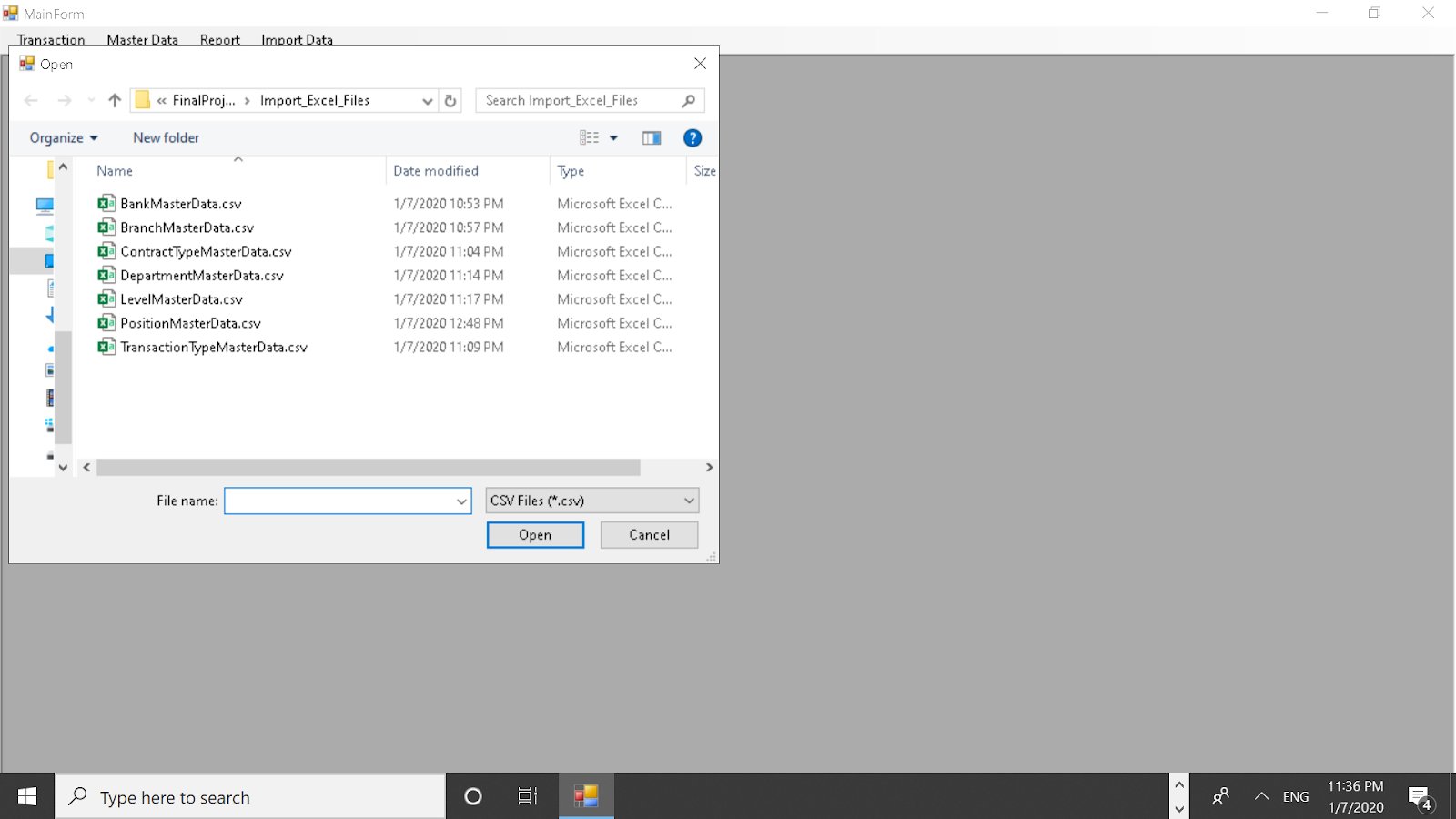
Importing CSV Files:
Imported data will be inserted into the database.
Database Security
User access management
There is only one admin set to work within the database. This admin controls users underneath it. Meaning the admin has the power to limit or grant more access to the database if so required. In a company setting it means that a singular admin or super admin can delegate parts of the work to their underlings. Since this is targeted towards HR, an HR manager can give some access to the employee. This access can vary from just view only or (write and view). The default is view only. This means that some other employees that don’t need to edit can use it as a reference for views. Furthermore this prevents unauthorized personnel from compromising the data within the database.
SQL injection countermeasures
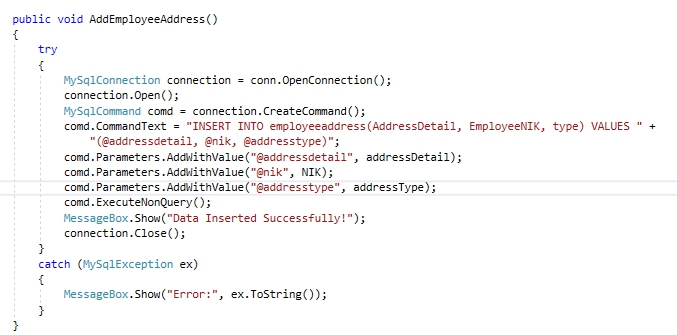
The code incorporates methods to counteract SQL injections. The main one being the handling of Prepared Statements. Look at the screenshot below
As you can parameters addwithvalue is added within the code which would mean that the user is forced to to insert the data in at least a suitable form so if for example a query added DROP TABLE query after the original query it would not register as that and would instead simply be a string therefore preventing major vulnerabilities in the form of SQL injections.
The above screenshot also shows the username and password countermeasures against sql injections. As seen in the screenshot username and password being the likely target of injections have addwithvalue functions thereby creating a barrier for sql injections from running within the server. Furthermore, it also adds an if function that checks if the correct username and password is detected to prevent users with unauthorized privileges from disrupting the data
CONCLUSION
In conclusion we were tasked with creating a database based on a certain company’s excel spreadsheet that fulfills the same capabilities as the original spreadsheet. Through this spreadsheet we created an ERD that has all the required links while also fulfilling the criterias to be in third normal form. Afterwards we created the database within mysql and tested it to make sure it is in working condition. Lastly we then coded it within visual studio in order to create a cohesive UI that integrates this database with pre built queries.
I am responsible for designing a majority of the class models of the program and for most of the data management interface. I also contributed in the design of the database table with the other group members. I also handled most of the data insertion, retrieval, update and deletion functions and interactions with the database. I also created the employee management page which manages email, phone, address and job history.
I am responsible for designing a majority of the class models of the program and for most of the data management interface. I also contributed in the design of the database table with the other group members. I also handled most of the data insertion, retrieval, update and deletion functions and interactions with the database. I also created the employee management page which manages email, phone, address and job history.